БмУт LEFT JOIN КЭ NULL
ЕБШЛЃЌгаКмЖрЪБКђФњашвЊжДаа LEFT JOIN КЭЪЙгУ NULL жЕЁЃЕЋЪЧЃЌЫќУЧВЂВЛЪЪгУгкЫљгаЧщПіЁЃИФБф SQL ВщбЏЕФЙЙНЈЗНЪНПЩФмЛсВњЩњНЋвЛИіЛЈМИЗжжгдЫааЕФБЈИцЫѕЖЬЕНжЛЛЈМИУыжгетбљЕФЬьШРжЎБ№ЕФаЇЙћЁЃгаЪБЃЌБиаыдкВщбЏжаЕїећЪ§ОнЕФаЮЬЌЃЌЪЙжЎЪЪгІгІгУГЬађЫљвЊЧѓЕФЯдЪОЗНЪНЁЃЫфШЛ TABLE Ъ§ОнРраЭЛсМѕЩйДѓСПеМгУзЪдДЕФЧщПіЃЌЕЋдкВщбЏжаЛЙгааэЖрЧјгђПЩвдНјаагХЛЏЁЃSQL ЕФвЛИігаМлжЕЕФГЃгУЙІФмЪЧ LEFT JOINЁЃЫќПЩвдгУгкМьЫїЕквЛИіБэжаЕФЫљгаааЁЂЕкЖўИіБэжаЫљгаЦЅХфЕФааЁЂвдМАЕкЖўИіБэжагыЕквЛИіБэВЛЦЅХфЕФЫљгаааЁЃР§ШчЃЌШчЙћЯЃЭћЗЕЛиУПИіПЭЛЇМАЦфЖЈЕЅЃЌЪЙгУ LEFT JOIN дђПЩвдЯдЪОгаЖЈЕЅКЭУЛгаЖЈЕЅЕФПЭЛЇЁЃ
ДЫЙЄОпПЩФмЛсБЛЙ§ЖШЪЙгУЁЃLEFT JOIN ЯћКФЕФзЪдДЗЧГЃжЎЖрЃЌвђЮЊЫќУЧАќКЌгы NULLЃЈВЛДцдкЃЉЪ§ОнЦЅХфЕФЪ§ОнЁЃдкФГаЉЧщПіЯТЃЌетЪЧВЛПЩБмУтЕФЃЌЕЋЪЧДњМлПЩФмЗЧГЃИпЁЃLEFT JOIN БШ INNER JOIN ЯћКФзЪдДИќЖрЃЌЫљвдШчЙћФњПЩвджиаТБраДВщбЏвдЪЙЕУИУВщбЏВЛЪЙгУШЮКЮ LEFT JOINЃЌдђЛсЕУЕНЗЧГЃПЩЙлЕФЛиБЈЁЃ
МгПьЪЙгУ LEFT JOIN ЕФВщбЏЫйЖШЕФвЛЯюММЪѕЩцМАДДНЈвЛИі TABLE Ъ§ОнРраЭЃЌВхШыЕквЛИіБэЃЈLEFT JOIN зѓВрЕФБэЃЉжаЕФЫљгаааЃЌШЛКѓЪЙгУЕкЖўИіБэжаЕФжЕИќаТ TABLE Ъ§ОнРраЭЁЃДЫММЪѕЪЧвЛИіСНВНЕФЙ§ГЬЃЌЕЋгыБъзМЕФ LEFT JOIN ЯрБШЃЌПЩвдНкЪЁДѓСПЪБМфЁЃвЛИіКмКУЕФЙцдђЪЧГЂЪдИїжжВЛЭЌЕФММЪѕВЂМЧТМУПжжММЪѕЫљашЕФЪБМфЃЌжБЕНЛёЕУгУгкФњЕФгІгУГЬађЕФжДааадФмзюМбЕФВщбЏЁЃ
ВтЪдВщбЏЕФЫйЖШЪБЃЌгаБивЊЖрДЮдЫааДЫВщбЏЃЌШЛКѓШЁвЛИіЦНОљжЕЁЃвђЮЊВщбЏЃЈЛђДцДЂЙ§ГЬЃЉПЩФмЛсДцДЂдк sql server ФкДцжаЕФЙ§ГЬЛКДцжаЃЌвђДЫЕквЛДЮГЂЪдКФЗбЕФЪБМфКУЯёЩдГЄвЛаЉЃЌЖјЫљгаКѓајГЂЪдКФЗбЕФЪБМфЖМНЯЖЬЁЃСэЭтЃЌдЫааФњЕФВщбЏЪБЃЌПЩФме§дкеыЖдЯрЭЌЕФБэдЫааЦфЫћВщбЏЁЃЕБЦфЫћВщбЏЫјЖЈКЭНтЫјетаЉБэЪБЃЌПЩФмЛсЕМжТФњЕФВщбЏвЊХХЖгЕШД§ЁЃР§ШчЃЌШчЙћФњНјааВщбЏЪБФГШЫе§дкИќаТДЫБэжаЕФЪ§ОнЃЌдђдкИќаТЬсНЛЪБФњЕФВщбЏПЩФмашвЊКФЗбИќГЄЪБМфРДжДааЁЃ
БмУтЪЙгУ LEFT JOIN ЪБЫйЖШНЕЕЭЕФзюМђЕЅЗНЗЈЪЧОЁПЩФмЖрЕиЮЇШЦЫќУЧЩшМЦЪ§ОнПтЁЃР§ШчЃЌМйЩшФГвЛВњЦЗПЩФмОпгаРрБ№вВПЩФмУЛгаРрБ№ЁЃШчЙћ Products БэДцДЂСЫЦфРрБ№ЕФ IDЃЌЖјУЛгагУгкФГИіЬиЖЈВњЦЗЕФРрБ№ЃЌдђФњПЩвддкзжЖЮжаДцДЂ NULL жЕЁЃШЛКѓФњБиаыжДаа LEFT JOIN РДЛёШЁЫљгаВњЦЗМАЦфРрБ№ЁЃФњПЩвдДДНЈвЛИіжЕЮЊ"No Category"ЕФРрБ№ЃЌДгЖјжИЖЈЭтМќЙиЯЕВЛдЪаэ NULL жЕЁЃЭЈЙ§жДааЩЯЪіВйзїЃЌЯждкФњОЭПЩвдЪЙгУ INNER JOIN МьЫїЫљгаВњЦЗМАЦфРрБ№СЫЁЃЫфШЛетПДЦ№РДКУЯёЪЧвЛИіДјгаЖргрЪ§ОнЕФБфЭЈЗНЗЈЃЌЕЋПЩФмЪЧвЛИіКмгаМлжЕЕФММЪѕЃЌвђЮЊЫќПЩвдЯћГ§ SQL ХњДІРэгяОфжаЯћКФзЪдДНЯЖрЕФ LEFT JOINЁЃдкЪ§ОнПтжаШЋВПЪЙгУДЫИХФюПЩвдЮЊФњНкЪЁДѓСПЕФДІРэЪБМфЁЃЧыМЧзЁЃЌЖдгкФњЕФгУЛЇЖјбдЃЌМДЪЙМИУыжгЕФЪБМфвВЗЧГЃживЊЃЌвђЮЊЕБФњгааэЖргУЛЇе§дкЗУЮЪЭЌвЛИіСЊЛњЪ§ОнПтгІгУГЬађЪБЃЌетМИУыжгЪЕМЪЩЯЕФвтвхЛсЗЧГЃжиДѓЁЃ
СщЛюЪЙгУЕбПЈЖћГЫЛ§
ЖдгкДЫММЧЩЃЌЮвНЋНјааЗЧГЃЯъЯИЕФНщЩмЃЌВЂЬсГЋдкФГаЉЧщПіЯТЪЙгУЕбПЈЖћГЫЛ§ЁЃГігкФГаЉдвђЃЌЕбПЈЖћГЫЛ§ (CROSS JOIN) дтЕНСЫКмЖрЧДд№ЃЌПЊЗЂШЫдБЭЈГЃЛсБЛОЏИцИљБООЭВЛвЊЪЙгУЫќУЧЁЃдкаэЖрЧщПіЯТЃЌЫќУЧЯћКФЕФзЪдДЬЋЖрЃЌДгЖјЮоЗЈИпаЇЪЙгУЁЃЕЋЪЧЯё SQL жаЕФШЮКЮЙЄОпвЛбљЃЌШчЙће§ШЗЪЙгУЃЌЫќУЧвВЛсКмгаМлжЕЁЃР§ШчЃЌШчЙћФњЯыдЫаавЛИіЗЕЛиУПдТЪ§ОнЃЈМДЪЙФГвЛЬиЖЈдТЗнПЭЛЇУЛгаЖЈЕЅвВвЊЗЕЛиЃЉЕФВщбЏЃЌФњОЭПЩвдКмЗНБуЕиЪЙгУЕбПЈЖћГЫЛ§ЁЃ
ЫфШЛетПДЦ№РДКУЯёУЛЪВУДЩёЦцЕФЃЌЕЋЪЧЧыПМТЧвЛЯТЃЌШчЙћФњДгПЭЛЇЕНЖЈЕЅЃЈетаЉЖЈЕЅАДдТЗнНјааЗжзщВЂЖдЯњЪлЖюНјаааЁМЦЃЉНјааСЫБъзМЕФ INNER JOINЃЌдђжЛЛсЛёЕУПЭЛЇгаЖЈЕЅЕФдТЗнЁЃвђДЫЃЌЖдгкПЭЛЇЮДЖЉЙКШЮКЮВњЦЗЕФдТЗнЃЌФњВЛЛсЛёЕУ 0 жЕЁЃШчЙћФњЯыЮЊУПИіПЭЛЇЖМЛцжЦвЛИіЭМЃЌвдЯдЪОУПИідТКЭИУдТЯњЪлЖюЃЌдђПЩФмЯЃЭћДЫЭМАќРЈдТЯњЪлЖюЮЊ 0 ЕФдТЗнЃЌвдБужБЙлБъЪЖГіетаЉдТЗнЁЃШчЙћЪЙгУ Figure 2ЃЈзюКѓвЛвГЃЉ жаЕФ SQLЃЌЪ§ОндђЛсЬјЙ§ЯњЪлЖюЮЊ 0 УРдЊЕФдТЗнЃЌвђЮЊдкЖЈЕЅБэжаЖдгкСуЯњЪлЖюВЛЛсАќКЌШЮКЮааЃЈМйЩшФњжЛДцДЂЗЂЩњЕФЪТМўЃЉЁЃ
Figure 3ЃЈзюКѓвЛвГЃЉжаЕФДњТыЫфШЛНЯГЄЃЌЕЋЪЧПЩвдДяЕНЛёШЁЫљгаЯњЪлЪ§ОнЃЈЩѕжСАќРЈУЛгаЯњЪлЖюЕФдТЗнЃЉЕФФПБъЁЃЪзЯШЃЌЫќЛсЬсШЁШЅФъЫљгадТЗнЕФСаБэЃЌШЛКѓНЋЫќУЧЗХШыЕквЛИі TABLE Ъ§ОнРраЭБэ (@tblMonths) жаЁЃЯТвЛВНЃЌДЫДњТыЛсЛёШЁдкИУЪБМфЖЮФкгаЯњЪлЖюЕФЫљгаПЭЛЇЙЋЫОЕФУћГЦСаБэЃЌШЛКѓНЋЫќУЧЗХШыСэвЛИі TABLE Ъ§ОнРраЭБэ (@tblCus-tomers) жаЁЃетСНИіБэДцДЂСЫДДНЈНсЙћМЏЫљБиашЕФЫљгаЛљБОЪ§ОнЃЌЕЋЪЕМЪЯњЪлЪ§СПГ§ЭтЁЃ ЕквЛИіБэжаСаГіСЫЫљгадТЗнЃЈ12 ааЃЉЃЌЕкЖўИіБэжаСаГіСЫетИіЪБМфЖЮФкгаЯњЪлЖюЕФЫљгаПЭЛЇЃЈЖдгкЮвЪЧ 81 ИіЃЉЁЃВЂЗЧУПИіПЭЛЇдкЙ§ШЅ 12 ИідТжаЕФУПИідТЖМЙКТђСЫВњЦЗЃЌЫљвдЃЌжДаа INNER JOIN Лђ LEFT JOIN ВЛЛсЗЕЛиУПИідТЕФУПИіПЭЛЇЁЃетаЉВйзїжЛЛсЗЕЛиЙКТђВњЦЗЕФПЭЛЇКЭдТЗнЁЃ
ЕбПЈЖћГЫЛ§дђПЩвдЗЕЛиЫљгадТЗнЕФЫљгаПЭЛЇЁЃЕбПЈЖћГЫЛ§ЛљБОЩЯЪЧНЋЕквЛИіБэгыЕкЖўИіБэЯрГЫЃЌЩњГЩвЛИіааМЏКЯЃЌЦфжаАќКЌЕквЛИіБэжаЕФааЪ§гыЕкЖўИіБэжаЕФааЪ§ЯрГЫЕФНсЙћЁЃвђДЫЃЌЕбПЈЖћГЫЛ§ЛсЯђБэ @tblFinal ЗЕЛи 972 ааЁЃзюКѓЕФВНжшЪЧЪЙгУДЫШеЦкЗЖЮЇФкУПИіПЭЛЇЕФдТЯњЪлЖюзмМЦИќаТ @tblFinal БэЃЌвдМАбЁдёзюжеЕФааМЏЁЃ
ШчЙћгЩгкЕбПЈЖћГЫЛ§еМгУЕФзЪдДПЩФмЛсКмЖрЃЌЖјВЛашвЊеце§ЕФЕбПЈЖћГЫЛ§ЃЌдђПЩвдНїЩїЕиЪЙгУ CROSS JOINЁЃР§ШчЃЌШчЙћЖдВњЦЗКЭРрБ№жДааСЫ CROSS JOINЃЌШЛКѓЪЙгУ WHERE згОфЁЂDISTINCT Лђ GROUP BY РДЩИбЁГіДѓЖрЪ§ааЃЌФЧУДЪЙгУ INNER JOIN ЛсЛёЕУЭЌбљЕФНсЙћЃЌЖјЧваЇТЪИпЕУЖрЁЃШчЙћашвЊЮЊЫљгаЕФПЩФмадЖМЗЕЛиЪ§ОнЃЈР§ШчдкФњЯЃЭћЪЙгУУПдТЯњЪлШеЦкЬюГфвЛИіЭМБэЪБЃЉЃЌдђЕбПЈЖћГЫЛ§ПЩФмЛсЗЧГЃгаАяжњЁЃЕЋЪЧЃЌФњВЛгІИУНЋЫќУЧгУгкЦфЫћгУЭОЃЌвђЮЊдкДѓЖрЪ§ЗНАИжа INNER JOIN ЕФаЇТЪвЊИпЕУЖрЁЃ
ЪАвХВЙСу
етРяНщЩмЦфЫћвЛаЉПЩАяжњЬсИп SQL ВщбЏаЇТЪЕФГЃгУММЪѕЁЃМйЩшФњНЋАДЧјгђЖдЫљгаЯњЪлШЫдБНјааЗжзщВЂНЋЫћУЧЕФЯњЪлЖюНјаааЁМЦЃЌЕЋЪЧФњжЛЯывЊФЧаЉЪ§ОнПтжаБъМЧЮЊДІгкЛюЖЏзДЬЌЕФЯњЪлШЫдБЁЃФњПЩвдАДЧјгђЖдЯњЪлШЫдБЗжзщЃЌВЂЪЙгУ HAVING згОфЯћГ§ФЧаЉЮДДІгкЛюЖЏзДЬЌЕФЯњЪлШЫдБЃЌвВПЩвддк WHERE згОфжажДааДЫВйзїЁЃдк WHERE згОфжажДааДЫВйзїЛсМѕЩйашвЊЗжзщЕФааЪ§ЃЌЫљвдБШдк HAVING згОфжажДааДЫВйзїаЇТЪИќИпЁЃHAVING згОфжаЛљгкааЕФЬѕМўЕФЩИбЁЛсЧПжЦВщбЏЖдФЧаЉдк WHERE згОфжаЛсБЛШЅГ§ЕФЪ§ОнНјааЗжзщЁЃ
СэвЛИіЬсИпаЇТЪЕФММЧЩЪЧЪЙгУ DISTINCT ЙиМќзжВщевЪ§ОнааЕФЕЅЖРБЈБэЃЌРДДњЬцЪЙгУ GROUP BY згОфЁЃдкетжжЧщПіЯТЃЌЪЙгУ DISTINCT ЙиМќзжЕФ SQL аЇТЪИќИпЁЃЧыдкашвЊМЦЫуОлКЯКЏЪ§ЃЈSUMЁЂCOUNTЁЂMAX ЕШЃЉЕФЧщПіЯТдйЪЙгУ GROUP BYЁЃСэЭтЃЌШчЙћФњЕФВщбЏзмЪЧздМКЗЕЛивЛИіЮЈвЛЕФааЃЌдђВЛвЊЪЙгУ DISTINCT ЙиМќзжЁЃдкетжжЧщПіЯТЃЌDISTINCT ЙиМќзжжЛЛсдіМгЯЕЭГПЊЯњЁЃ
ФњвбОПДЕНСЫЃЌгаДѓСПММЪѕЖМПЩгУгкгХЛЏВщбЏКЭЪЕЯжЬиЖЈЕФвЕЮёЙцдђЃЌММЧЩОЭЪЧНјаавЛаЉГЂЪдЃЌШЛКѓБШНЯЫќУЧЕФадФмЁЃзюживЊЕФЪЧвЊВтЪдЁЂВтЪдЁЂдйВтЪдЁЃдкДЫзЈРИЕФНЋРДИїЦкФкШнжаЃЌЮвНЋМЬајЩюШыНВЪі SQL Server ИХФюЃЌАќРЈЪ§ОнПтЩшМЦЁЂКУЕФЫїв§ЪЕМљвдМА SQL Server АВШЋЗЖР§ЁЃ
ЙиМќДЪБъЧЉЃКЗНЗЈ,адФм,ЬсИп,ЪЙгУ,
ЯрЙидФЖС
ШШУХЮФеТ
 SqlServer2005ЖдЯжгаЪ§ОнНјааЗжЧјОпЬхВНжш
SqlServer2005ЖдЯжгаЪ§ОнНјааЗжЧјОпЬхВНжш sql serverЯЕЭГБэЫ№ЛЕЕФНтОіЗНЗЈ
sql serverЯЕЭГБэЫ№ЛЕЕФНтОіЗНЗЈ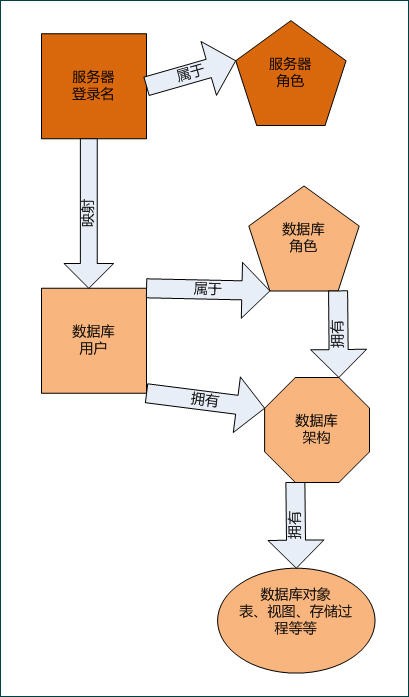 MS-SQL2005ЗўЮёЦїЕЧТМУћЁЂНЧЩЋЁЂЪ§ОнПтгУЛЇ
MS-SQL2005ЗўЮёЦїЕЧТМУћЁЂНЧЩЋЁЂЪ§ОнПтгУЛЇ AccessЁЂSQL ServerЁЂOracleГЃМћгІгУЕФЧјБ№
AccessЁЂSQL ServerЁЂOracleГЃМћгІгУЕФЧјБ№
ШЫЦјХХаа ШчКЮдЖГЬБИЗнЃЈЛЙдЃЉSQL2000Ъ§ОнПтХфжУКЭзЂВсODBCЪ§ОндД-odbcЪ§ОндДХфжУНЬГЬSQL2000Ъ§ОнПтдЖГЬЕМШыЃЈЕМГіЃЉЪ§ОнSQL2000КЭSQL2005Ъ§ОнПтЗўЮёЖЫПкВщПДЛђаоИФSQL Server 2005НЕМЖЕН2000ЕФе§ШЗВйзїВНжшаоИФSql ServerЮЈвЛдМЪјНЬГЬЧГЬИJSP JDBCРДСЌНгSQL Server 2005ЕФЗНЗЈSQL ServerДДНЈБэгяОфНщЩм
ВщПДЫљга0ЬѕЦРТл>>